Source: here.
The Rāmāyaṇa in numbers: meters, sarga- and kāṇḍa- structure
Context of rAmAyaNa
In the extant Indo-European textual corpus, only in the Hindu collection do we find two complete early epics to complement the śruti. The Iranian epics come from a much later age than the core Avestan corpus, and in the Greek and Celtic cases, the śruti-equivalents have been mostly or entirely lost. As they have come down to us, the Hindu epics postdate much of the Vedic corpus but are still in a distinct language register that largely predates the classical Sanskrit. Thus, the numerical study of the epics gives us essential information regarding the evolution of the Old Indo-Aryan language and compositional technique, with general implications for earlier branching events within Indo-European. Contrary to the deeply flawed mainstream white indological opinion (and its imitators), and in line with Hindu tradition, we hold that the original Rāmāyaṇa was composed prior to the Mahābhārata. However, it is also clear that both epics were at some point “held” by the same expositors and redactors, resulting in some convergences. We had earlier presented some key details about the structure of Rāmāyaṇa and the earliest para-Rāmāyaṇa (the Rāmopākhyāna) via numerical analysis and pointed out how the kāṇḍa-s show both a certain unity and divergence relating to the compositional history of the epic. Here, we extend that analysis further and draw some inferences regarding the above-stated issues.
Data
The so-called Baroda “critical edition” is available in an electronic format and forms the basis of the below analysis. We have corrected several errors in that text; however, we cannot rule out that some errors remain, affecting some of the below numbers. Nevertheless, these will not affect any of the basic inferences presented below.
Meter
The
Rāmāyaṇa is mostly a metrical text with 17810 verses having 2
hemistiches each. There are 79 verses with 1 hemistich, i.e., standalone
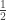
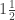
Table 1
| Syllables | Frequency | Meter |
|---|---|---|
| 32 | 16949 | Anuṣṭubh (Śloka) |
| 44 | 476 | Triṣṭubh (Upendravajrā) |
| 48 | 285 | Jagati (Vaṃśastha) |
| 50 | 26 | Puṣpitāgrā |
| 45 | 22 | |
| 47 | 20 | |
| 46 | 16 | Aparavaktrā etc. |
| 33 | 8 | |
| 52 | 7 | Rucirā |
The primary meters are given in the third column with major, specific subtypes in brackets. It should be noted that the type in the bracket is just a widespread version and not the sole version found in the epic. For example, we have triṣṭubh-s of other types like jāyā, buddhi, kīrti, etc. in addition to the common upendravajra. Likewise, with the jagati-s we have versions like kumārī in addition to the prevalent Vaṃśastha. The dominant meter is, of course, the śloka anuṣṭubh. Now, some verses do not match any meter. Since we did not individually check all of them, some may be errors in the preparation of the electronic text — indeed, we corrected several of these.
However, some of the 33s are genuine hypermetrical anuṣṭubh-s, like the famous ancient statement in the second hemistich that is hypermetrical:
idaṃ bhuṅkṣva mahārāja
prīto yad-aśanā vayam ।
yad annaḥ puruṣo bhavati
tad annās tasya devatāḥ ॥O great king, be pleased and partake this, such food as we [eat],
for the gods are offered the [same] as what food the man takes.
The 45 syllabled verses seem to be hypermetrical triṣṭubh-s, and the 47
syllabled ones seem to be primarily hypometrical jagati-s. Thus, there
appears to be a total of about 50 hypo/hyper-metrical verses among the
“properly formed” verses 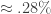
The 46 syllabled verse is a bit of a mystery. Many of these can be shown to be aparavaktrā-s; however, several do not match the aparavaktrā properly. It is not clear if these were variant aparavaktrā-s that are no longer in vogue or an error of transcription or something else.
Rgveda contrast
This pattern of strong metricality is in contrast to the Veda. Looking at the most metrical of the Vedic texts, the Ṛgveda, we find below distribution (Figure 1).
 Figure
Figure
- Frequency of verses of a given syllable count in the Ṛgveda.
The RV widely uses the Gāyatrī meter (2nd most common) that fell out of vogue in the later Sanskrit tradition. However, the other widely used meters Anuṣṭubh (4th most common), Triṣṭubh (most common) and Jagati (3rd most common), are shared with the epic tradition. We also have internal evidence from the śruti that their syllable count was precisely as in the later dialect, like in the epic. Hence, it is striking to note that, unlike in the epic, the meter is far more loosely maintained in the RV, with a dominance of hypometrical verses.
This suggests that whereas the Rāmāyaṇa was composed more or less in the same dialect as it has come down to us, the RV was likely originally composed in an older dialect closer to the PI-Ir state, with a distinct system of saṃdhi-s than in later Sanskrit.+++(5)+++
The language in which it has come down to us has shifted in register closer to later Sanskrit, with the new saṃdhi-s resulting in losses of syllables from the old language. In a smaller number of cases, this shift in register has also resulted in the likely resolution of old saṃdhi-s and consequent hypermetricality.+++(4)+++ This shall be separately discussed in the future in the context of the Veda.
kANDa relation
We shall next look at the distribution of the different meters in each kāṇḍa per 1000 proper verses in Table 2.
Table 2

Based on this distribution we can compute the Euclidean distance between kāṇḍa-s and construct an unrooted single linkage tree (Figure 2).
 Figure
2. Relationship between kāṇḍa-s based on distribution of meters.
Figure
2. Relationship between kāṇḍa-s based on distribution of meters.
To better understand the above groupings, we next go down to the sarga level and compute two metrics for each sarga in a kāṇḍa:
- (1) metrical heterogeneity, i.e., the mean syllable count per sarga and
- (2) length of a sarga in number of verses (as previously discussed).
The metrical heterogeneity measures how “pure” a sarga is in terms of the meter. For example, a sarga composed entirely of Anuṣṭubh-s will have metrical heterogeneity of 32. We show the plots of these metrics in Figure 3.

Figure 3. Sarga heterogeneity metrics by kāṇḍa.
Here, we can see that the kāṇḍa-s 1 and 7 are dominated by sarga-s with pure Anuṣṭubh-s of similar mean length, explaining their grouping in the tree. The kāṇḍa-s 2, 3, and 4 are somewhat more heterogeneous in terms of their metrical structure and have similar mean lengths consistent with their grouping. Finally, kāṇḍa-s 5 and 6 are metrically the most heterogeneous with on an average significantly longer sarga-s. This structure and grouping throw some light on the history of the text.
Kāṇḍa 1 (Bāla) states that Vālmīki composed the epic in 6 kāṇḍa-s along with an “uttara” or addendum: tathā sarga-śatān pañca ṣaṭ kāṇḍāni tathottaram ॥ (From Vulgate; absent in “Critical”). This hints that there was a memory of the uttara-kāṇḍa (7) as an addendum to the core 6.+++(5)+++ This is apparent from the nature of several parts of kāṇḍa-7, which fill in the narrative gaps in the core kāṇḍa-s or provide explanatory commentary.
The same feature is evident in kāṇḍa 1 (including the above statement). Their grouping, together with an anuṣṭubh-rich structural uniformity reminiscent of the purāṇika verses, suggests that they are likely entirely (7) or partly (1) the product of a later redactional effort to fill in parts of the epic that were either lost or needed further explanation/augmentation. Even the supposed names of the sons of Rāma, Kuśa and Lava, appear to be derived from an old term for a minstrel, the kuśīlava (the twins are mentioned as such in the beginning of 1 and end of 7), suggesting the emergence of these parts within the oral tradition of such minstrels, which used the relatively-easy-to-compose anuṣṭubh-s uniformly. Kāṇḍa 1 also hints that the original epic had two subsections to it:
kāvyaṃ rāmāyaṇaṃ kṛtsnaṃ
sītāyāś caritaṃ mahat ।
paulastya vadham ity evaṃ
cakāra caritavrataḥ ॥He (Vālmīki) composed the great poem, the Rāmāyaṇa, the story of Sītā.
Even so, he of firm vows composed that known as the slaying of the Paulastya.
We could interpret this as implying two larger sections of the narrative centered on the tale of Sītā (i.e., her birth and marriage to Rāma, etc.) and the killing of Rāvaṇa. Thus, we suspect the two structurally unified parts the kāṇḍa-s 2-4 (probably with parts of the ancestral 1) formed the first of these sections, and kāṇḍa-s 5-6, which are again structurally similar, and organically related to the killing of Rāvaṇa, formed the second.+++(5)+++
Kāṇḍa 5 (Sundara), which shows maximal metrical and length heterogeneity, was likely composed thus on purpose (as we noted before). This kāṇḍa foreshadows the tendency in later classical kāvya, where the kavi-s set aside specific sections of their work, to showcase their virtuosity in terms of composing in a diverse array of meters or displaying various alaṃkāra-s, including citrakāvya.+++(5)+++ We do not see the much longer and complex metrical expressions of classical kāvya nor the constraint-based composition using techniques of citrakāvya in the Sundarakāṇḍa. Yet, it is clear that Kāṇḍa 5 elegantly intersperses diverse meters on top of the basic anuṣṭubh background to bring about pleasing changes of cadence. Like later kāvya-s, it also has entire sarga-s in long meter-s.
sarga-s
Next, we study the structure of the sarga-s by themselves and see if we can discern:
- (1) specific structural classes of sarga-s;
- (2) whether the sarga class has a relationship to the kāṇḍa it comes from.
To do this, we first construct a matrix where every row corresponds to a sarga. The first 9 columns correspond to the fractions of the sarga in verses of a particular number of syllables (32, 33, 44 etc.). Column 10 corresponds to the length of the sarga in number of verses normalized by the longest sarga (5.1). We then use this matrix for unsupervised classification of the sarga-s using the random forest predictor as implemented by Breiman and Cutler.
Briefly, this is a machine-learning method that uses an
ensemble of individual classification tree predictors (i.e., decision
trees to classify the given data). The decision process specified by an
individual tree uses each observation to vote for one “class” and the
forest of such trees is used to choose the class with the plurality of
votes. For the classification process, the number of randomly selected
variables that are searched for deciding the best split at each node in
the tree is taken to be
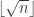

The unsupervised mode works by making
the RF predictor discriminate the observed (i.e., the above sarga matrix
in our case) from synthetically produced data. The synthetic data is
made by randomly sampling from the product of marginal distributions of
the variables from our input matrix. As a result, one can obtain a
proximity matrix between the input observations (i.e., sarga-s in our
case). This proximity matrix can be converted to a distance matrix and
used as the input for multidimensional scaling (MDS), representing the
observations as points in an Euclidean space of
 Figure
4
Figure
4
We see 4 broadly delineated clusters, although their “smearing” indicates a degree of a continuum. Examining each cluster individually, we see that they provide a meaningful classification of the sarga-s:
- (1) The first class (ellipse to the left) is composed of sarga-s that are pure anuṣṭubh-s.
- (2) The second class (top right ellipse) comprises of sarga-s that have anuṣṭubh-s combined with triṣṭubh-s. The core of this class is defined by a very characteristic form of the sarga that contains a triṣṭubh as the capping (final) verse.
- (3) The third class (bottom right ellipse) consists of sarga-s combining anuṣṭubh-s with jagati-s. The core of this class uses a jagati, usually of the vaṃśastha type, as the capping verse.
- (4) Finally, the central ellipse contains a group of sarga-s typified by interspersing of different meters on an anuṣṭubh background or those with irregular (hypo/hyper-metrical) verses.
 Figure
5
Figure
5
One can see from the color-coding of the sarga-s by kāṇḍa in Figure 4
that there might be distinct patterns — e.g., class 1 appears enriched
in kāṇḍa-s 1 and 7, which are rare in the other classes. Hence, we next
examined if each of the above classes differ significantly in terms of
the kāṇḍa-s from which their sarga-s are drawn (Figure 5). This confirms
that the kāṇḍa-s 1 and 7 dominate class 1 
Another notable feature that
emerges is the enrichment of kāṇḍa 2 in the class with jagati capping
verses 